

 強化学習について学んでみた。(その8) - いものやま。
強化学習について学んでみた。(その8) - いものやま。昨日はグリーディ法とグリーディ法を扱った。 今日はn本腕バンディット問題に対する別のアルゴリズムを考えていく。 ソフトマックス法 グリーディ法では、探査を行うために、の確率でランダムに行動を選択していた。 もう一つ、探査を行うための方法として、推定される行動の価値の比率に応じて行動を選択するという方法が考えられる。 すなわち、推定される行動の価値から、価値が高そうな行動はより選ばれやすく、価値が低そうな行動は選ばれにくく(けど、全く選ばれないわけではないように)なる確率にしたがって行動を選択する。 そうすれば、基本的には価値が高いと思われる行動が選ばれ、たまに他の行動の探査も行われるようになる。 このようなアルゴリズムを、ソフトマックス法(ソフトマックス行動選択)と呼ぶ。 ソフトマックス法の具体的な方策(ポリシー)の一つは、次のようになる。 上記のは温度と呼ばれる学習パラメータで、温度が高

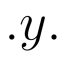 強化学習について学んでみた。(その1) - いものやま。
強化学習について学んでみた。(その1) - いものやま。
