
kaggleパッケージをインストールして、VS Codeの統合ターミナルからKaggle APIにkaggleコマンド を使ってアクセスし、ローカル環境でKaggleノートブックを実行してみましょう。

 番外編:VS CodeでKaggleしよう!
番外編:VS CodeでKaggleしよう!
kaggleパッケージをインストールして、VS Codeの統合ターミナルからKaggle APIにkaggleコマンド を使ってアクセスし、ローカル環境でKaggleノートブックを実行してみましょう。

 Kaggle初心者のためのコンペガイド ― Titanicの先へ
Kaggle初心者のためのコンペガイド ― Titanicの先へ
Kaggle初心者がKaggleに挑戦した過程や得られた知見などを記事化していく新連載。初回である今回は、準備編として初心者向けにコンペを簡単に紹介します。また、連載目的やKaggleを始めて「これが良かったよ」という筆者の体験を共有します。 連載目次 機械学習やディープラーニングを勉強してきて、書籍やWeb上のコンテンツで用意された練習問題から、より実践的な問題で腕を磨きたいと思ったときに、データサイエンス/機械学習の世界的なコンペティション(以下、コンペ)プラットフォームであるKaggleや日本のSIGNATEを使ってみようと考えている人は少なくないと思います。そして書籍やWeb情報を基に、KaggleでTitanicコンペでSubmission(提出)をしてみた後、次はどんなコンペに参戦しようかを迷う人も少なくないのではないでしょうか? そんな人に向けて今回は、既に終わっているコンペ

 挑戦! word2vecで自然言語処理(Keras+TensorFlow使用)
挑戦! word2vecで自然言語処理(Keras+TensorFlow使用)
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。 ディープラーニングと自然言語処理 画像認識や音声認識の分野では、すでに圧倒的ともいえる成果を誇っているのがディープラーニングである。猫画像識別のニュースに驚かされてからわずか数年のうちに、例えば「GAN(Generative Adversarial Network)」という技術が開発されていて、これを使うと、文字どおり何もないところから写真と見まがう画像を生成することができる。まさに、「十分に進歩した科学は魔法と区別がつかない」。 では、ディープラーニングのもう一方の有力分野である自然言語処理の状況はど

 TensorFlow 2+Keras(tf.keras)入門
TensorFlow 2+Keras(tf.keras)入門
機械学習の勉強はここから始めてみよう。ディープラーニングの基盤技術であるニューラルネットワーク(NN)を、知識ゼロの状態から概略を押さえつつ実装。さらにCNNやRNNも同様に学ぶ。これらの実装例を通して、TensorFlow 2とKerasにも習熟する連載。 第1回 初めてのニューラルネットワーク実装、まずは準備をしよう ― 仕組み理解×初実装(前編)(2019/09/19) ニューラルネットワークは難しくない ディープラーニングの大まかな流れ 1データ準備 ・Playgroundによる図解 ・Pythonコードでの実装例 2問題種別 ・Playgroundによる図解 ・Pythonコードでの実装例 3前処理 ・Playgroundによる図解 ・訓練用/精度検証用のデータ分割について ・ノイズについて ・Pythonコードでの実装例 第2回 ニューラルネットワーク最速入門 ― 仕組み理解×

 第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け)
第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け)
第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け):TensorFlow 2+Keras(tf.keras)入門(1/2 ページ) TensorFlow 2.x(2.0以降)では、モデルの書き方が整理されたものの、それでも3種類のAPIで、6通りの書き方ができる。今回は初心者~初中級者にお勧めの、SequentialモデルとFunctional APIの書き方、全3通りについて説明する。 連載目次 前回までの全3回では、ニューラルネットワークの仕組みや挙動を図解で示しながら、TensorFlow(tf.keras)による基本的な実装方法を説明した。しかし実際には、TensorFlowの書き方はこれだけではない。 TensorFlowにおける、3種類/6通りのモデルの書き方 3種類のAPI 大きく分けて、下記の3種類があることを第2回で説明済みである。 Seq

 第1回勉強会:なぜ今MLOpsなのか、先駆者や実際の現場からMLOpsを学ぼう
第1回勉強会:なぜ今MLOpsなのか、先駆者や実際の現場からMLOpsを学ぼう
連載目次 MLOpsコミュニティーは「全ての機械学習モデルが現場で実運用化される世界」を目指して2020年夏に始まりました。月1回程度の頻度での活動を目指し、勉強会やワークショップ、ディスカッションなどを行うことで、今後のAI技術の発展に非常に重要な、MLOps(機械学習の実運用化)の普及に貢献していきます。 このレポートでは、2020年8月に行われた第1回勉強会の様子をお伝えします。300人以上の参加者がリモートで参加し、大盛況のイベントとなりました。当日の様子はツイッターでも盛んにつぶやかれ、こちらにそのまとめがあります。 なぜ今MLOpsなのか by シバタアキラ はじめに、オーガナイザーチームの一人である、DataRobot Japanのシバタアキラから、なぜ今MLOpsが注目されているのかをお話しました。まず300人以上にGoToWebinarのアンケート機能を使って質問しました

 第9回 機械学習の評価関数(回帰/時系列予測用)を使いこなそう
第9回 機械学習の評価関数(回帰/時系列予測用)を使いこなそう
連載目次 前々回は回帰問題、前回は分類問題の解き方を解説した。それぞれの評価時における精度指標(Metrics)として、回帰問題では平均絶対誤差(MAE)を、分類問題では正解率(Accuracy)を用いた。これらは、最も基礎的で一般的な評価関数(Metric function)である。実践では、より多様な評価関数を使い分けることになるだろう。 そこで今回は、回帰問題や時系列予測(後述)で使える代表的な評価関数をまとめる。具体的には、下記の7つの評価関数を説明する。 本稿は、一通り目を通すことでざっくりと理解したら、あとは必要に応じて個別に参照するという「辞書的な使い方」を推奨する。といっても、上記の順番で違いを意識しながら理解すればそれほど難しくはないので安心してほしい。 時系列予測について 本連載では、ここまで回帰(Regression)と分類(Classification)については説

 バイアスとバリアンス(偏りと分散)のトレードオフ(Bias-Variance Tradeoff)とは?
バイアスとバリアンス(偏りと分散)のトレードオフ(Bias-Variance Tradeoff)とは?
バイアスとバリアンス(偏りと分散)のトレードオフ(Bias-Variance Tradeoff)とは?:AI・機械学習の用語辞典 用語「偏りと分散のトレードオフ」について説明。機械学習モデルによる予測において汎化誤差を最小化させるために、偏り誤差を小さくするとバラツキ(分散)誤差が大きくなり、逆にバラツキ誤差を小さくすると偏り誤差が大きくなるという、両者のトレードオフの関係性を示す。 連載目次 用語解説 機械学習(や統計学)のモデルによる予測においてバイアス(偏り:Bias)とは、予測値と真の値(=正解値)とのズレ(つまり「偏り誤差:Bias error」)を指す。この予測誤差は、モデルの仮定に誤りがあることから生じる(※なお、ニューラルネットワークのニューロンおける重みとバイアスの「バイアス」とは別物なので注意)。 またバリアンス(分散:Variance)とは、予測値の広がり(つまり「ば

 PyTorch/TensorFlow/Keras/scikit-learnライブラリ内蔵のデータセット一覧
PyTorch/TensorFlow/Keras/scikit-learnライブラリ内蔵のデータセット一覧
PyTorch/TensorFlow/Keras/scikit-learnライブラリ内蔵のデータセット一覧:AI・機械学習のデータセット辞典 機械学習やディープラーニング用の主要ライブラリが提供する「画像/音声/テキストなどのデータセット」の名前とリンクを表にまとめ、典型的な使い方を簡単に紹介する。 連載目次 本連載「AI・機械学習のデータセット辞典」では、ここまで主に、scikit-learnやKeras/TensorFlow(tf.keras)、TensorFlow Datasets、PyTorchといった主要なPythonライブラリに共通的に含まれる代表的なデータセットを紹介し、各ライブラリでの典型的な実装コード例を示してきた。しかし、これらの全ライブラリに共通的に含まれているデータセットはまれで非常に少ない。よってこれからは、個々のライブラリに1つしか含まれていないようなこまごまと

 Web更新情報が手軽にとれるRSSの仕組み ― @IT
Web更新情報が手軽にとれるRSSの仕組み ― @IT
「RSSをとる」「RSSでチェックする」など、IT企業の会話に紛れ込んできているRSSという概念。RSSの効果、技術の仕組みを分かりやすく5分で説明します RSSがない時代は大変! いきなり「RSS」といわれても、知らない人にはどんな技術なのかさっぱり分かりません。しかし、何の略語かを知れば簡単に想像できます。「RSS」は「Rich Site Summary」(*1)の略語で、直訳すると「充実したWebサイトの要約」といった意味になります。RSSとは、その名前のとおりニュースサイトやブログなど、Webサイトの見出しや要約をまとめてくれる技術なのです。 技術的な解説をする前に、RSSが登場したことによって、Webの更新がどれだけ便利になったか振り返ってみましょう。数年前、現在のようなRSSがなかった時代は、Webサイトチェックはなかなか大変でした。当時のWeb巡回方法は……、 Webブラウザ

 プログラムを関数にまとめて、実行結果をグラフにプロットしよう
プログラムを関数にまとめて、実行結果をグラフにプロットしよう
Netクラスは「CNNなんて怖くない! その基本を見てみよう」の最後で紹介したコードを(ほぼ)そのまま使用しています。 学習や精度の評価を行うコードも基本的にはこれまでと同様で、それらを関数にまとめただけなので、コードを見て、「難しい……」と思うことはあまりないと思います。ただし、今回は合計6万個の学習用の手書き数字を訓練に使うものと、精度の評価に使うものに分割してみましょう。テスト用の手書き数字は、精度評価が終わったニューラルネットワークモデルに入力して、それが未知のデータに対しても汎用的に使えるかどうかの確認に使います。 訓練データを分割して、それぞれに対応するデータローダーを作成するために、今回は上に示したget_loaders関数を定義することにしました。 また、今回は1エポック(6万個のデータ)の学習と精度評価を複数回繰り返して、学習を進めるたびにニューラルネットワークモデルがど

 「機械学習の最先端」を効率的に情報収集! おすすめのメルマガ3選
「機械学習の最先端」を効率的に情報収集! おすすめのメルマガ3選
機械学習/ディープラーニングの進化は速い。どうやってその最新技術情報に追いつけばよいのか。そんな状況の中、実際に筆者が実践活用して役立っており、本心でお勧めできる3つのメルマガを紹介する。 連載目次 現在の「人工知能/機械学習」分野は、新たな技術が次々と生まれるホットな領域の一つである。ただし、その最先端の情報を追いかけるのは容易ではない。 その理由の一つが、最先端技術の情報はさまざまな場所/人から発信され、しかも膨大な情報量であるためだ。それら全ての情報源と情報量をウォッチするのは難しいし、Twitter上で情報を追いかけるにしても、大量の玉石混交の情報が流れており、なかなか思いどおりに効率よくは必要十分な情報が手に入らない(という人は多いのではないだろうか)。特に論文に載ったばかりの知見や、海外(特に米国)で流れている重要技術情報をキャッチするのは大変である。 筆者も一日に2時間ぐらい

 もはやPoCばかりやっている場合ではない――企業が抱くAIへの誤解と課題
もはやPoCばかりやっている場合ではない――企業が抱くAIへの誤解と課題
あらゆる分野で活用が広がる人工知能(AI)技術。中でもDeep Learning(以下、DL)は画像処理や映像処理での活用に始まり、Googleが2018年10月に発表した「BERT」をきっかけに、自然言語処理(NLP)分野でも進化が進むなど、できることは日々広がっている。こうした技術を企業がビジネスに活用していく際に直面する課題とは何だろうか。ABEJAの代表取締役兼CEOであり、日本ディープラーニング協会(JDLA)の理事を務める岡田陽介氏に聞いた。 技術的な課題よりも、AIに対する「根強い誤解」が課題に? 今やさまざまなメディアで「AIを活用すべき」「機械学習(以下、ML)やDLを生かした新しいビジネスを」といった論調が飛び交っているが、自社でどのように取り入れ、実践すべきか、思い悩む企業は少なくないのではないだろうか。岡田氏によると、データやテクノロジーの活用を考える際にまず重要な

 TensorFlow入門
TensorFlow入門
TensorFlowを使ってディープラーニングの基礎が体験できる連載。TensorFlowの概要から、インストール方法、CNN/RNNモデルの実装体験、TensorBoardの使い方までを解説する。 全8回【完結】 ( 3時間30分) 必須条件: 機械学習の基礎知識が必要です(※「深層学習 入門」参照)。 自前のPCか、クラウド環境を使う必要があります。GPUがなくてもOKです(TensorFlowのCPU版/GPU版、両対応です)。GPUを使う場合、事前に環境を構築してください(※「環境構築 入門」参照)。 Windows/macOS/Ubuntuに対応しています。 高校レベルの数学の知識が必要ですが、理解できなくても体験可能。 こんな方にお勧め: ディープラーニングを体験してみたい方 TensorFlowを体験し、その基礎知識を身に付けたい方 CNN(畳み込みニューラルネットワーク)を

 MNISTの手書き数字を全結合型ニューラルネットワークで処理してみよう
MNISTの手書き数字を全結合型ニューラルネットワークで処理してみよう
MNISTデータベースには、上に示したような手書きの数字(と対応する正解ラベル)が訓練データとして6万個、テストデータとして1万個格納されています。この膨大な数のデータを使用して、手書きの数字を認識してみようというのが目標です。 今回は、これまでに見てきた全結合型のニューラルネットワークを作成して、これを実際に試してみましょう。今回紹介するコードはここで公開しているので、必要に応じて参照してください。 データセットの準備と探索 本連載で使用している機械学習フレームワークであるPyTorchには今述べたMNISTを手軽に扱えるようにするためのtorchvisionパッケージが用意されています(「vision」が付いているのは、このパッケージがコンピューターによる視覚の実現=コンピュータービジョンに由来するのでしょう)。このパッケージを使って実際にMNISTデータベースからデータセットを読み込

 [Python入門]Pythonコーディングスタイルガイド
[Python入門]Pythonコーディングスタイルガイド
PEP 8とは PEP(Python Enhancement Proposal)とは、Pythonの新機能に関する仕様やその背景を、Pythonコミュニティーに対して提供する文書のことだ。これまでに数多くのPEPが発行されているが、その中でPEP 8は「Style Guide for Python Code」と銘打ち、Pythonコードを記述する際の決めごとを定めたものとなっている。 Pythonは誰が書いても同じようなコードとなりやすいように作られた言語だが、そうはいってもコードの書き方そのものが言語仕様上でガチガチに定められているわけではない。例えば、if文を例に取れば、同じコードでも次のような書き方ができる。 if節の本体を改行なしで書くこともできるし、空白文字はある程度自由にコード中に含めることもできる。どんな書き方をするかは、プログラマーに一任されている。だが、これでは誰の目にも
![[Python入門]Pythonコーディングスタイルガイド](https://cdn-ak-scissors.b.st-hatena.com/image/square/1ec962e4979d8c2eac1f9862e2ae753f304a1b2b/height=288;version=1;width=512/https%3A%2F%2Fimage.itmedia.co.jp%2Fait%2Farticles%2F1912%2F10%2Fcover_news045.png)
リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


 100のサービスを10カテゴリーに分類、アイスマイリーが「データ分析AIカオスマップ」を公開
100のサービスを10カテゴリーに分類、アイスマイリーが「データ分析AIカオスマップ」を公開
 VS Codeでエンコーディングを変更、自動判別するには
VS Codeでエンコーディングを変更、自動判別するには
 MNIST:手書き数字の画像データセット
MNIST:手書き数字の画像データセット
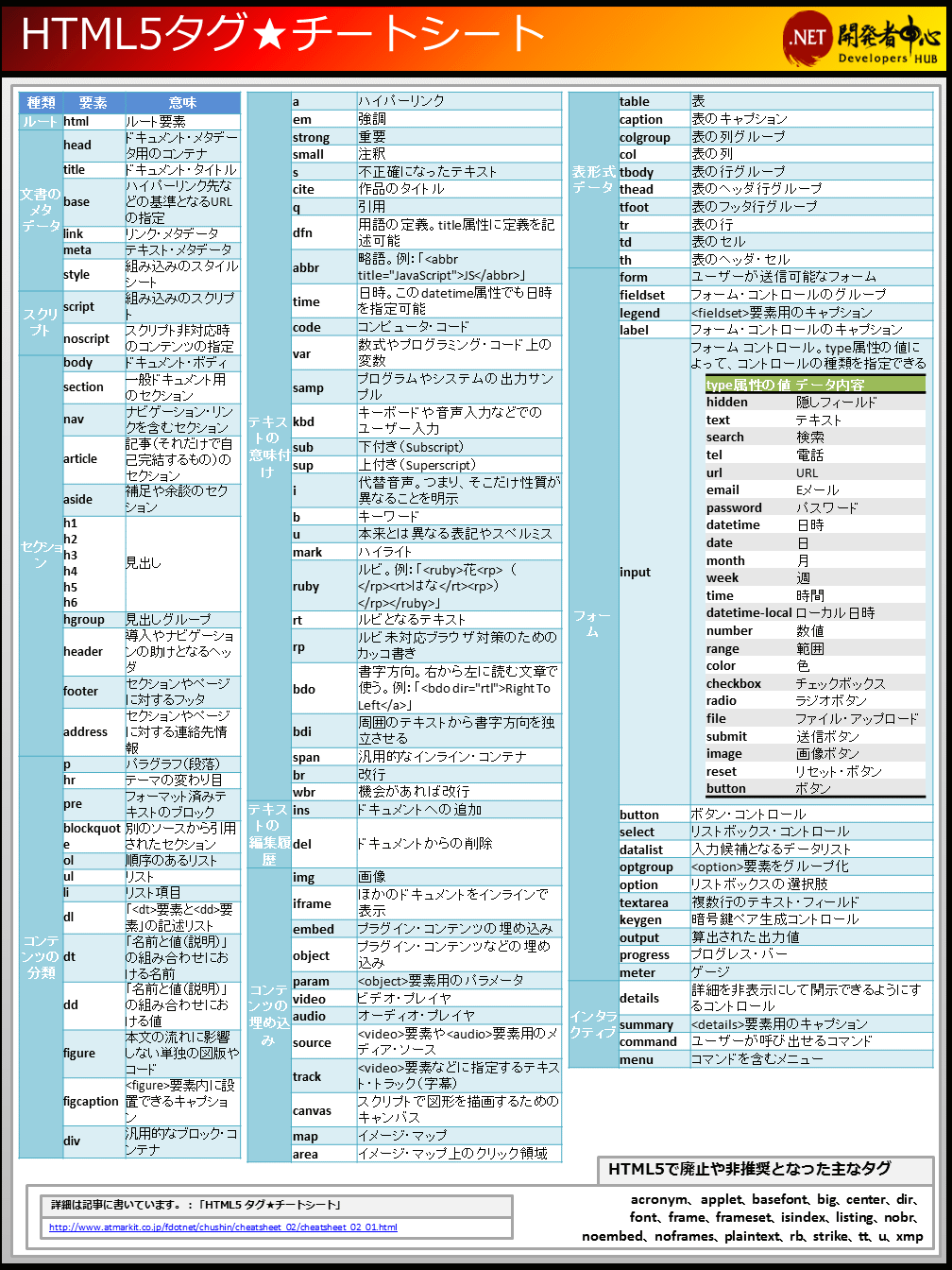 https://atmarkit.itmedia.co.jp/fdotnet/chushin/cheatsheet_02/cheatsheet_02_01.gif
https://atmarkit.itmedia.co.jp/fdotnet/chushin/cheatsheet_02/cheatsheet_02_01.gif{kind=link}