 「Unicode 8.0」で肌の色の多様性に対応へ、“絵文字”に肌の色を変化させる符号を追加 -INTERNET Watch
「Unicode 8.0」で肌の色の多様性に対応へ、“絵文字”に肌の色を変化させる符号を追加 -INTERNET Watch


昨日のエントリ(「iPhoneのMailから送ったメッセージ全体が文字化け」のまとめ)読みましたよー。iPhoneから送るメールの文字化け防止策は、署名に「♡」を入れておけばOKなんですよね? うん。ただまあ、ちょっと気にする人はいるかもなあ。 男子に誤解されちゃう、と? いや、そういうのじゃなくて、つまり、化けちゃうんだよね。 えっ? 相手の環境によっては「♡」が化けるんだよ。 何ですかそれ。文字化け対策で入れた文字が化けたら意味ないじゃないですか。 意味はあるよ。iPhoneから送ったメールは相手先で全体が化けて読めなくなる可能性があるけど、「♡」でcharset=UTF-8にしておけば、この「全体化け」を防げるんだから。ただし、相手がケータイだったりすると、「♡」自体は「・」とか「?」とかになっちゃうってこと。 自らは捨て石となってメッセージ全体を救うということですか。UTF-8にな

日本語EUC(EUC-JP)にはいろいろあって頭がこんがらがってきたので、サルにもわかるように(つまり、自分があとから見て理解できるように)まとめてみた*1。まず、EUC-JPにはどんな種類があるのだろうということで、わたしの環境で実装例を確認できるものをピックアップしてみた。下図のうちeucJP-openとIANAのEUC-JPについては身近な実装例を思いつかなかったが、これを外すわけにはいかないだろうと思って入れておいた。 各EUC-JPのレパートリをまとめたのが、下図。eucJP-openには上図に示したようなバリエーションがあるが、レパートリは共通。「JIS X 0208の国際基準版・漢字用8ビット符号 + JIS X 0201片仮名」については、これを一言で表現できる呼称を思いつかないので、以下の図では仮に「TextEdit」と表記する。 下図は、各EUC-JPのレパートリと符号

 Servlet Garden » Unicode and Character Sets (Translation)
Servlet Garden » Unicode and Character Sets (Translation)
勉強を兼ねての勝手に翻訳シリーズ第3弾です。今回はJoel Spolsky氏のブログに掲載されていたThe Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)です。掲載されたのは2003年10月と、5年近く前のことなので、現状にそぐわないところもあるかもしれませんが、とても参考になる解説です。 ソフトウェ開発者なら絶対に最低限知っていなければならないユニコードと文字セットについて(言い訳はなしですよ!) 不可解なContent-Typeタグについてかつて疑問に思ったことはないでしょうか?おそらくHTMLファイルに書き込むものということは知ってるでしょうが、なんのためにそれなければいけないのかまでは知ら
UnicodeがASCIIを追い越し、World Wide Web上で最も多く利用されている文字コード体系になったとGoogleのシニアインターナショナルソフトウェアアーキテクトMark Davis氏がブログで述べている。また、UnicodeはASCIIだけでなく、Western Europeanもほぼ同時に追い越している。 Unicodeは多くの言語に対応した標準文字コード体系で、発音区別符号などを利用したローマ字なども扱っている。何十年も前に定められたASCIIコードは128文字あるいは256文字(ASCIIで128 文字、拡張ASCIIで256文字)しか表現できず、タイプライターの影響を受けた同文字コードの拡張は苦戦している。 UnicodeがASCIIとWestern Europeanを追い越したのは12月で、双方が追い越された日は10日も違わなかった。 Unicodeの動きについ

2009年08月07日15:00 カテゴリCode Unicode - JISマークは一文字! 私もびっくりしたのですが、事実です。 まずは以下をご覧下さい。 〄は一文字です(U+3004)。 フォントまわりをカスタマイズしていないIEでも表示を確認できました。UbuntuのFirefoxでは空白でしたが。 なぜ気がついたかと言えば、unicode@unicode.org にこんな書き込みが登場したからです。 At http://en.wikipedia.org/wiki/Japanese_Industrial_Standards, a new symbol for JIS is shown and discussed. Will there be a new character in the Standard? (Not a new glyph in the same codepoint

ソフトウェアの日本語文字が中華フォントに侵食されていて想像以上の危機らしい「違和感すごい」 というのが盛り上がっていた。 「想像以上」は主観的だけど、個人的にはちょっと煽りすぎのように思った。 前提: Han Unification はひっくりかえせない そもそも、UTF-8 がよく使われるようになって、絵文字もはいった UCS で、Han Unification しなくてもいいのでは、という話はある。 でもこれは後の祭りで、今更ひっくりかえすのは無理だと思うので、ここでは検討しません。 ユーザー側の言語情報を参照すれば、日本語のグリフは選べる ほとんどの OS には、このユーザーの言語はこれですよ、という情報があって、それでメニューやボタンの文字が日本語になる。日付の表示方法とかも、これを参照する。統合漢字でも日本語のグリフでレンダリングしたい、というのは、8割くらいはこれで解決するはな
たとえば「○か×か」というテキストをヒラギノで表示した際、「×」だけが小さく見えて困惑したといった経験を、多くのMac OS Xユーザが持っていると思う。これは、ヒラギノがU+00D7 MULTIPLICATION SIGN(乗算記号)をプロポーショナルでデザインしているためである。そんなわけで、JIS X 0208の範囲内のいわゆる「全角文字」のうち、ヒラギノでは全角でデザインされていない文字のリスト(ヒラギノ丸ゴ Pro W4、バージョン7.11で表示)を作成してみた。目で見て拾っただけなので、漏れなどがあるかもしれない。 このうちセント記号(U+00A2 CENT SIGN)、ポンド記号(U+00A3)、否定記号(U+00AC)がプロポーショナルなのは、Unicodeの範囲内には他に全角バージョン(U+FFE0 FULLWIDTH CENT SIGN、U+FFE1 FULLWIDTH

 クメール文字とUnicode
クメール文字とUnicode
無 @LGRikka 今日の4限は、Unicodeにクメール文字を入れたとき、どれだけ揉めたかという話だったのだけれど、なかなかそれが複雑な問題を孕んでいたので、自分用の整理がてら連続ツイートしようかなと。 無 @LGRikka 「主にカンボジアで使われるクメール文字をUnicodeに入れようとしたとき、カンボジアの言語学者どころかカンボジア人が誰もいない状態で、文字コードの専門家(外国人)だけが集まってリストを作ったせいで、ワケわからん文字は入ってるわ、必要な文字はないわのウンコードになった」っていう。

2024-04-17: ICU 75 is now available. It updates to CLDR 45 (beta blog) locale data with new locales and various additions and corrections. C++ code now requires C++17 and is being made more robust. The CLDR MessageFormat 2.0 specification is now in technology preview, together with a corresponding update of the ICU4J (Java) tech preview and a new ICU4C (C++) tech preview. See Downloading ICU > ICU
 Unicode Character Search
Unicode Character Search
Unicode Character Search Query: include Han codepoints? Cancel A-Z index | Search options
ケータイの絵文字について、各キャリアの「他社用変換表」を見ると、ゲタにするよりはマシだろうということなのだろうが、けっこう強引というか、感覚的な対応も多く、ラウンドトリップの互換性は保証されない。 つまり、絵文字入りのメールを他社ケータイに送信し、さらにそれを引用して送信するというプロセスを繰り返した場合、伝言ゲームのように少しずつ絵文字の意味がズレていく可能性がある。 というわけで下図は、適当に拾った例で、絵文字がどんなふうに変化していくのかシミュレートしたもの(16進数はShift-JISコード)。文脈によっては、キケンなニュアンスに変わったりすることもあるかも。

 xrecode - Converter for MP3,WAV,OGG,WMA,FLAC,APE,WavPack,CUE files with full unicode support.
xrecode - Converter for MP3,WAV,OGG,WMA,FLAC,APE,WavPack,CUE files with full unicode support.
XRECODE3 is audio converter, which supports most of the common audio formats, such as mp3, wav, flac, dsd, etc. It also supports extracting audio file from most video files as well as Audio-CD grabbing. Command Line parameters are supported. Please visit Forum and Wiki for more information on how to use the program.
英ケンブリッジ大学コンピュータ研究所は11月1日(現地時間)、「Trojan Source:Invisible Vulnerabilities」(リンク先はPDF)という論文を公開した。Trojan Sourceは、「人間のコードレビュアーには見えないターゲットを絞った脆弱性を作成するためのクールな新トリック」という。 研究者のロス・アンダーソン氏は、「Unicodeの方向性オーバーライド文字を使って、コードを別のロジックのアナグラムとして表示するこの攻撃は、C、C++、C#、JavaScript、Java、Rust、Go、Pythonに対して機能することを確認しており、他のほとんどの言語に対しても機能すると思われる」と説明する。 「人間が見るのと異なるロジックをコンパイラに示せるように、ソースコードファイルのエンコーディングを操作する方法を発見した」。コメントや文字列に埋め込まれた制御文

こないだ同僚に Unicode のサロゲートペアについて説明する機会があって、それで Unicode の話をブログ記事に書きたくなったのでサロゲートペアについて書いておこうと思う。 この記事は Unicode Standard version 6.3.0 を見ながら書いた。 文字とコードポイント 抽象文字 (abstract character) を計算機上で扱うためには、符号化する必要がある。 Unicode では、文字の符号化のために使用できる整数の範囲を コード空間 (Codespace; 符号空間) と呼んでいる。 0 から 0x10FFFF がその範囲である。 そして、その空間に属する値を コードポイント (Code Point; 符号位置) と呼ぶ。 次の図は、抽象的な 「Å」 という文字と、対応する 符号化文字 (Encoded Character) を表現するコードポイント

文字コードが引き起こすセキュリティ上の問題として、もっとも興味深いもののひとつである、Unicodeから他の文字コードへの「多対一の変換」で引き起こされる問題点について、今回と次回で説明します。 ご存じのとおり、Unicodeには非常に多数の文字が収録されていますが(現在最新版のUnicode 5.1.0では100,713文字が収録されているそうです)、Unicodeから他の文字コードへの変換においては、互換性や可読性の維持のためか、複数のUnicodeの文字が他の文字コードでは単一の文字に変換されることがあります。 この「多対一」の変換が、開発者も想定していなかったような問題を引き起こす原因となることが多々あります。 具体的な例として、Windows上でのUnicodeからの変換について説明します。 Windows上でのUnicodeからShift_JISへの変換 Windows上で
![第7回 Unicodeからの多対一の変換[前編] | gihyo.jp](https://cdn-ak-scissors.b.st-hatena.com/image/square/762fdaf17889a9d833f0bd06908e69f5624e1f46/height=288;version=1;width=512/https%3A%2F%2Fgihyo.jp%2Fassets%2Fimages%2FICON%2F2009%2F343_charcode.png)
 Pythonと日本語表示と文字コード、unicode 、str 、utf-8 、shift-jis 、、、 - Cassiopeiaの日記
Pythonと日本語表示と文字コード、unicode 、str 、utf-8 、shift-jis 、、、 - Cassiopeiaの日記
Pythonは使いやすい覚えやすい気持ちいいとまで言う人もいる。たしかにその通りだと思った。しかし、日本語を使おうとした時に急に気持ち良くなくなる。そう感じたのは僕だけではないはずだ。 ということで今日の日記のネタはPythonと日本語となりました。 (WindowsXPにココから "Python 2.5.1 Windows installer" をインストールした環境でテストしています。) まずは、あなたが書いたコードはutf-8で保存する。そして、そのコードの先頭には以下を記入する。 # -*- coding: utf-8 -*- あなたはエディタに何を使っていますか? 秀丸、メモ帳、vim、meadow、或いは Python Scripter、eclipse ? いずれにしてもファイルを保存する時のエンコードはutf-8にすべし。 では早速気持ちよくない(表示が文字化けする!)例。

 Lionにナマハゲと天狗が入っているのはどうして? - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
Lionにナマハゲと天狗が入っているのはどうして? - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
Appleカラー絵文字って何? iPhoneやLionに搭載されている絵文字フォントの名前だよ。Lionをインストールすると、iPhoneのカラー絵文字がMacでも使えるようになるんだ。文字ビューアの「絵文字」から入力できるよ。 iPhoneとLionでは、絵文字に違いはあるの? いちばん目立つ違いは、Lionでは文字が増えてることかな。 わあ、どんなのが増えたの? ナマハゲとか天狗とかナルトとか。 これ、モノクロじゃん。 増えてるぶんは、ぜんぶモノクロ。Lionは、Unicodeに収録されたケータイ絵文字のうち、Softbank絵文字以外を、いわば「docomo/au互換絵文字」としてモノクロでサポートしている*1。このモノクロの絵文字は、文字ビューアの「絵文字」には表示されない。Font Bookでレパートリーを表示すると、下のほうに入ってるよ。 Gmailを使えば、以前からMacでも

Unicode の雪だるま Unicode Snowman for You というサイトを知りました。Unicode の雪だるま (U+2603 SNOWMAN ☃) が表示されるだけのサイトです。が、ソースを見ると font-face で EOT 形式のウェブフォントが使われていることに気づきました。 この EOT (Embedded Open Type) 形式のウェブフォントは IE しか対応していないようです。IE で表示するとこのような雪だるまが表示されました。これはおそらく Arial Unicode MS の雪だるまです。ちょっとこわいような。。 一方、他のブラウザで表示すると、このような雪だるまが表示されました。これは私がデフォルトのフォントに設定しているメイリオの雪だるまです。これはかわいい。意外なところにも力が入っています。
Mountain Lionで新幹線の絵文字が変わりましたねー。 うん。といっても、Appleカラー絵文字には、新幹線の疑いがある車両が4つほどあるんだけどね。 う、疑いですか? ほら、こんなかんじ。 いや、上の2つは新幹線でしょうけど……。 U+1F689 STATIONなんて、看板にはっきりと「新幹線」て書いてあるじゃん。 書いてあっても違います。 ふーん。U+1F686 TRAINは逆に、どこにも新幹線とは書いてないけど、車両のデザインは明らかにフランスのTGVだぞ。 でも、このレールの上で時速300キロとか出したらまずいことになりますよね? 非常にまずいだろうね。Lionには、もうちょっと丈夫そうなレールに乗ったTGVもあったんだけどね。 え? というわけで、新幹線の疑いがある車両の変遷をまとめると……。 あー、Mountain Lionでは0系で上書きされて消えちゃったのが、丈夫な

携帯電話・PHS6社は4月24日、キャリアメールとSMSで使える絵文字の数と種類の共通化を5月以降順次始めると発表した。従来は他社ユーザー宛てに送ったメールの絵文字が「〓」表示に置き換わるケースがあったが、今後は同じ文字が共通に表示されるようになる。 発表したのは、NTTドコモ、KDDI、沖縄セルラー電話、ソフトバンクモバイル、イー・アクセス、ウィルコム。

 OS X 10.8.2のMail.appで新種の文字化け - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
OS X 10.8.2のMail.appで新種の文字化け - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
この項10月5日追記。OS X v10.8.2追加アップデート1.0により、次項以下で言及している本文の文字化けは解消された(ローマ数字の「Ⅴ」が「㈸」に化けるのは仕様なので従来どおり)。アップデート後に受信したメッセージについては、本文・件名ともに化けない。ただし、受信済みのメッセージについては、アップデート後に本文の文字化けは直ったが、件名の文字化けは直らなかった(下図)*1。 OS X 10.8.2のMail.appでは、Windows外字入りのISO-2022-JPを受信すると、メッセージ全体が化けることがある*2。たぶん、下図ピンク地の文字が1つでも含まれていると、メッセージ全体が(まるでソースを表示しているように)化ける。 下図は、Thunderbirdから本文に「ローマ数字のⅤ」「ローマ数字のⅥ」と書いたメールを送信し、OS X 10.8.2のMail.appで受信・表示した

日本がCJK統合漢字拡張F1/F2に提案している文字には、すでにUCSに入っている漢字と見分けがつかない例がいくつもある。これらは、提案書*1に「Similar and Variation」として既存の文字の符号位置が記載されているものの一部であり、つまり、似ている漢字の存在は百も承知で提案しているわけだ。 以下、そのような例を拾ってみた。左右に並べた文字のうち「UCS」欄に符号位置が入っているほうが、既存のもの。個々の文字について述べることはしないが、要するに「別字の衝突であれば、形が同じでも別の符号を与える」ということだろう。 だが、ちょっと待ってほしい。それって実はものすごく根本的な方針転換じゃないですか? 「機」の簡体字の「机」も「つくえ」の「机」も、形が同じである以上、同じ符号位置(U+673A)に包摂・統合するというのがCJK統合漢字の大原則であったはず*2。ここでいきなりそれ

 「iPhoneのMailから送ったメッセージ全体が文字化け」のまとめ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
「iPhoneのMailから送ったメッセージ全体が文字化け」のまとめ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
(2013年10月追記1)iOS 7の登場以来、このエントリへのアクセスが増えているので、情報を追加。iSO 7では、以前はauのiPhoneなどでしか発生しなかった「送信したcharset=CP932のメールが、Android端末で化ける」現象が、SoftBank iPhoneでも発生するようになった。詳しくは「iOS 7にしたら送信したメッセージが化けるようになった」を参照。 (2013年10月追記2)実際に確認できてはいないのだが、iOS 7の仕様変更により、iPhoneのメールアプリからSoftBankのケータイに絵文字を含むメールを送った場合、メッセージ全体が化けるのではないかと思われる(これに該当する経験をお持ちの方、コメント欄などで情報をいただけるとありがたいです)。 (2013年10月追記3)iOS 7がらみで(メッセージ全体が化けるのではなく)絵文字が表示されない問題につ

 Python 2/3 両対応のために `unicode_literals` を使うべきか - methaneのブログ
Python 2/3 両対応のために `unicode_literals` を使うべきか - methaneのブログ
背景 Python 2 用のコードを書くときは、 Python 3 対応を見越して # -*- coding: utf-8 -*- from __future__ import division, print_function, absolute_import をテンプレとして書いています。 __future__ はファイルごとにバラバラだと混乱を招くので、今関わってるプロジェクトでもこれを新規ファイルのテンプレとして登録してもらってます。 Python 3 の構文、リテラルを有効にする __future__ のうち、 unicode_literals だけは今まで使っていなかったのですが、ふと「あ、やっぱり使うべきだな」と思いついたので、そのへんをまとめます。 第三の文字列型 native string Python 2 には2つの文字列型 str (bytes) と unicode が

モンゴル文字は、主にモンゴル語表記のための文字*1である。縦書き専用の文字であり、日本語の場合とは反対に左から右へと行を進める。また、アラビア文字のように続け書きされ、文字が語のどの位置に来るかによって形が変わる。 モンゴル文字は現在も中国の内モンゴル自治区でモンゴル語の表記に現役で使用されている。他方モンゴル国ではソ連の影響下でモンゴル語の表記をキリル文字に切り替えたので、モンゴル文字は学校で習いはするものの一般にあまり使われない。 Unicode 3.0からモンゴル文字がシベ文字・トド文字・満州文字と統合されて収録されているため、コンピュータでこの文字を入力するにあたっては、独自の符号化方式を作成するのでなければUnicodeを利用しようとするのが当然に思える。しかし、現状のUnicodeモンゴル文字は致命的な欠陥を抱えている。 このエントリでは、2017年ころからUnicode Te

The way JavaScript handles Unicode is… surprising, to say the least. This write-up explains the pain points associated with Unicode in JavaScript, provides solutions for common problems, and explains how the ECMAScript 6 standard improves the situation. Unicode basics Before we take a closer look at JavaScript, let’s make sure we’re all on the same page when it comes to Unicode. It’s easiest to th
 Unicodeエスケープ - sawatのブログ
Unicodeエスケープ - sawatのブログ
付箋紙Greasemonkeyで、GM_setValueに登録した日本語の文字化け対策にencodeURIをつかったけど、encodeURIはURIをエンコードするための関数なのであんまり褒められた使い方ではないですね。しかも、encodeURIのようなURLエンコーディングは文字列をUTF-8にしてから、エンコード対象の各バイトを%xx形式*1で表現するので、日本語1文字をあらわすのにたいていの場合ASCII9文字が必要になって効率が悪いです。*2 なので、前述のような単に非ASCII文字をエスケープしたいだけのようなケースではUnicodeエスケープを使った方がよいです。Javaのpropertiesとかnative2asciiとかのやつです。 Unicodeエスケープは\uxxxx*3の形式であらわすので、たいていの日本語1文字はASCII6文字になって、URLエンコーディングに比べ

K.Takata @k_takata 「Unicode文字列型が複数の内部表現をサポート」ってどういうこと?「Python 2系からの移植を容易にするため…Unicodeリテラルシンタックスも復活」これは良い。 http://t.co/LxkUP45x 2012-03-06 21:44:00

 連絡先アプリに「バカ」とか登録しておくと死ぬの? - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
連絡先アプリに「バカ」とか登録しておくと死ぬの? - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
だれかにメールを出すとき、どんな宛名で届いてるのか、不安になることってないですか? ん、なんで? MacやiPhoneのメールって、表示されてる差出人や宛先を見ただけじゃ、本当はそこに何が書いてあるかわからないじゃないですか。で、気付かないうちに本人に見られたくない名前が送られちゃたりしないかな、と。 あー、たとえば「ほげ山」さんのメールアドレスを自分の連絡先には「バカ先生」って名前で登録してますみたいなこと? そういうの(下図)は危険だぞ。 こっちで「バカ先生」って表示されてるメールに返信すると、相手にも「バカ先生」で届くんですか? いや、そうとは限らなくて、けっこう複雑なんだよね。たとえば、連絡先に「バカ先生」が登録されている環境で、ほげ山さんからFrom欄に「ほげ山 」と書いてあるメールを受け取ったとすると、山ライオンやiOSのメールアプリでは、こんなふうに見える(下図)*1。リスト

 Win/Mac どちらの Excel でも正しく開ける Unicode な csv の出力方法 - Qiita
Win/Mac どちらの Excel でも正しく開ける Unicode な csv の出力方法 - Qiita
2018/11/27 追記 Excel for Mac 2016 のあるアップデートから UTF8-BOM が開けるようになったようです。 https://www.ka-net.org/blog/?p=7764 手元の 16.16.4 で試してみましたが開くことが出来ました。 平和になってよかったですね。 あらまし まず UTF-8 で吐いた csv を Excel で開いてみます。化けます。 仕方がないので BOM をつけてみます。 Win だと正しく開けました!でも Mac で化けます。 それならと UTF-16LE で吐いてみましょう。Win/Mac どちらも化けずに表示されました!これで大丈夫かと思いきやなんとカンマ区切りされず A 列に 1 行まるごと収まっています。死にます。 仕方がないので tsv で出力してみましょう。すごい!ちゃんと表示されています!でも .tsv はデフ

UnicodeとUTF-8、UTF-16との違いはなんでしょうか? ここでは、あまり詳細にはこだわらず、これらの概念を整理してみたいと思います。 まずUnicode。 これは文字集合です。アルファベットや記号はもちろん、漢字やひらがな、ハングルやヘブライ文字など、世界中で使われている文字を集めたものです。 次にUTF-8とUTF-16。 これらはUnicodeで定義されている一つ一つの文字を、どのように符号化するかという文字符号化方式(エンコーディング)です。 たとえば、Unicodeで定義されている「あ」という文字を、UTF-8とUTF-16で符号化すると下記のようになります(16進数表記)。 Unicodeという一つの文字集合に対して、異なる文字符号化方式UTF-8、UTF-16が存在し、符号化した結果も異なります。 どうしてUnicodeという一つの文字集合に対して、異なる文字符号化
MySQL 5.5.11 unicode_ci で同一視される文字 Unicode 002000A02000200120022003200420052006200720082009200A202F205F3000 Character Unicode 0021FE57FF01 Character !﹗! Unicode 0022FF02 Character "" Unicode 0023FE5FFF03 Character #﹟# Unicode 0024FE69FF04 Character $﹩$ Unicode 0025FE6AFF05 Character %﹪% Unicode 0026FE60FF06 Character &﹠& Unicode 0027FF07 Character '' Unicode 0028207D208DFE35FE59FF08 Character (⁽₍︵﹙
こんにちは。検索サービス開発2チームの斎藤です。休日は都内の美術館や博物館を巡り歩いています。 先日は池袋の古代オリエント博物館に行き、ハムラビ法典(のレプリカ)を見てきました。楔形文字はアシの筆を粘土板に押し当てて記述するものですが、ハムラビ法典は閃緑岩の石柱に彫られたそうです。「法典は石柱に彫ってね」と役人に無茶ぶりされて、当時の職人も「用途がちがーう」とか愚痴ったのかなぁ・・・と妄想してしまいました。 さて私の普段の業務ですが、NAVER LINEプロジェクトで絵文字やスタンプ関連の開発に携わっています。ちょうど楔形文字の話もしたところですので、このエントリでも絵文字の変換処理について解説させていただきます。 ドコモ/au/ソフトバンクの携帯電話(以下、フィーチャーフォン)で長く使われてきた絵文字も、2010年にUnicodeコンソーシアムによってUnicode 6.0で正式に定
 Ruby にて文字と Unicode コードポイントの相互変換を行う - vivid memo
Ruby にて文字と Unicode コードポイントの相互変換を行う - vivid memo
Unicode のコードポイントを指定して文字を得たり、逆にある文字のコードポイントを調べたり、ということをする機会は結構多いと思います。 が、Ruby でそれをやる方法をぐぐってもあまり上位に情報が出てこないなー、と思ったので簡単にまとめておきます。 Unicode コードポイントとは そもそも Unicode コードポイントとは何か。 Unicode というのは世界中の文字が集められた文字集合であり、Unicode に収録されている文字には順番に番号が振られています。 この番号のことをコードポイントといいます。 あるコードポイントが指す文字を表現するときに "U+" という文字の後ろに 16 進数表記のコードポイントを書いて表すことがあります。 例えば、コードポイント 0x3041 が指す文字 (ひらがなの 「あ」) を U+3041 と書いて表します。 各文字とコードポイントの関係は

 文字コード地獄秘話 第1話:Unicodeにおける全角・半角 - ALBERT Engineering Blog
文字コード地獄秘話 第1話:Unicodeにおける全角・半角 - ALBERT Engineering Blog
ごあいさつ 皆様はじめまして、文字コードおじさんです。細々とカメラ屋を営んでおりましたが、エンジニアとしての技量を評価され、ALBERTのシステム開発・コンサルティング部で働くことを許されました。特技はサーバーの統廃合です。 今回は最初ということですが、Unicodeにおける全角・半角の取り扱いについて触れてみようと思います。なお、さも連載するかのように第1話と銘打っていますが、上層部の無慈悲な裁決によっては1話打ち切りもありえますので、その際はご容赦ください。 固定観念を捨てよう 「全角50文字、半角100文字まで」といったような文言を見かけたことがあると思います。 特にUnicode以前のレガシーな処理系では全角文字に2バイト、それ以外は1バイトという割り当てが慣習となっていました。 このため、「全角=2バイト文字、半角=1バイト文字」という観念が世間に定着しているのが現状です。 しか

寒くなってきた今日このごろ、おでんが食べたくなったらUnicodeのU+1F362がある。 しかしU+1F362には大きな間違いがある。 それはUnicode Character Code ChartsのMiscellaneous Symbols and Pictographsに載っている。 seafood on skewer、日本語にすると「串に刺さったシーフード」である。 確実に僕の知っているおでんの定義じゃない。 念の為、「seafood on skewer」で画像検索してみる。 やっぱり僕の知らないおでんだった。 おまけ1 おでんの定義、ドラフト時には更によくわからなく、SEAFOOD CASSEROLE (Temporary Notes: seafood hotchpotch, oden)、日本語に訳すと「シーフード鍋料理(シーフードの鍋、おでん)」である。 SEAFOOD CA
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


 iPhoneの文字化けを防ぐ魔法の呪文 - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
iPhoneの文字化けを防ぐ魔法の呪文 - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 いろんな日本語EUCについてのまとめ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
いろんな日本語EUCについてのまとめ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 ウェブで利用される文字コード、UnicodeがASCIIを上回る--グーグルが明らかに
ウェブで利用される文字コード、UnicodeがASCIIを上回る--グーグルが明らかに
 Unicode - JISマークは一文字! : 404 Blog Not Found
Unicode - JISマークは一文字! : 404 Blog Not Found
 Google、オープンソースフォント「Noto」がUnicode標準をフルサポートしたことを明らかに
Google、オープンソースフォント「Noto」がUnicode標準をフルサポートしたことを明らかに

 Unicode をレンダリングするときは言語情報を渡しましょう - blog.8-p.info
Unicode をレンダリングするときは言語情報を渡しましょう - blog.8-p.info
 ヒラギノでは全角でデザインされていない文字 - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
ヒラギノでは全角でデザインされていない文字 - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 An Unicode vendor-specific character table for japanese (日本語のUnicodeベンダ依存文字表)
An Unicode vendor-specific character table for japanese (日本語のUnicodeベンダ依存文字表)
 ICU - International Components for Unicode
ICU - International Components for Unicode
 ケータイの絵文字はどこまでズレるのか - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
ケータイの絵文字はどこまでズレるのか - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 ソースコードに脆弱性を潜ませられるUnicode悪用攻撃法「Trojan Source」を研究者が発表
ソースコードに脆弱性を潜ませられるUnicode悪用攻撃法「Trojan Source」を研究者が発表
 Unicode のサロゲートペアとは何か - ひだまりソケットは壊れない
Unicode のサロゲートペアとは何か - ひだまりソケットは壊れない
 第7回 Unicodeからの多対一の変換[前編] | gihyo.jp
第7回 Unicodeからの多対一の変換[前編] | gihyo.jp
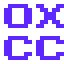 Unicode の雪だるま - bkブログ
Unicode の雪だるま - bkブログ
 ぼくらを乗せた新幹線はどこへ向かっているのか - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
ぼくらを乗せた新幹線はどこへ向かっているのか - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 携帯・PHS各社、メールの絵文字を共通化 Unicodeに対応
携帯・PHS各社、メールの絵文字を共通化 Unicodeに対応
 CJK統合漢字拡張Fがヤバイ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
CJK統合漢字拡張Fがヤバイ - 帰ってきた💫Unicode刑事〔デカ〕リターンズ
 現在のUnicodeモンゴル文字の問題点と最近の動き - にせねこメモ
現在のUnicodeモンゴル文字の問題点と最近の動き - にせねこメモ
 JavaScript has a Unicode problem · Mathias Bynens
JavaScript has a Unicode problem · Mathias Bynens
 西村賢さんのPython内部文字コードの話題から端を発するUnicodeの話
西村賢さんのPython内部文字コードの話題から端を発するUnicodeの話
 Amazon.co.jp: 世界の文字と記号の大図鑑 ー Unicode 6.0の全グリフ: ヨハネス・ベルガーハウゼン (著), シリ・ポアランガン (著), 小泉均 (監修): 本
Amazon.co.jp: 世界の文字と記号の大図鑑 ー Unicode 6.0の全グリフ: ヨハネス・ベルガーハウゼン (著), シリ・ポアランガン (著), 小泉均 (監修): 本

 Unicode ~UTF-8、UTF-16との違い~(文字コード関連) | 読み物 | ウナのIT資格一問一答
Unicode ~UTF-8、UTF-16との違い~(文字コード関連) | 読み物 | ウナのIT資格一問一答
 MySQL 5.5.11 unicode_ci で同一視される文字
MySQL 5.5.11 unicode_ci で同一視される文字
 Unicode 6.0を含めた絵文字変換を実現する « NAVER Engineer's Blog
Unicode 6.0を含めた絵文字変換を実現する « NAVER Engineer's Blog
 Unicodeで伝わる間違った日本文化 - Folioscope
Unicodeで伝わる間違った日本文化 - Folioscope