
Storytelling For The Web: Integrate Storytelling in your Design Process

 JPEGのDCTブロックで コンテンツ指向のトリミング
JPEGのDCTブロックで コンテンツ指向のトリミング
Storytelling For The Web: Integrate Storytelling in your Design Process

 [KMP77] を読んでみた - d.y.d.
[KMP77] を読んでみた - d.y.d.
17:53 14/12/22 ソートの逆流れ クイックソートってあるじゃないですか、クイックソート。 配列、たとえば [4,2,1,7,0,6,5,3] があったときに、 小さい方を左に、大きい方を右にまず適当に集める。 この「小さい方」と「大きい方」への二分割を、いわゆる再帰的に、 分かれたブロック両方で同じ事を繰り返していくと… なんと、小さい順に並んだ配列 [0,1,2,3,4,5,6,7] が出来上がるというアルゴリズムです。 逆向き! このデータの流れを「逆向きに」見てみたい。つまり、ソートが終わった最終状態から話が始まります。 しかも、さっきから説明なしで意味ありげにくっついていた、 「入力配列で元々どの位置にあったか」を表す値に注目していきます。 0の上に[4]がくっついているのは、最初は値0は配列のインデックス[4]の位置にあった、 ということを意味しています。(上のソート
![[KMP77] を読んでみた - d.y.d.](https://cdn-ak-scissors.b.st-hatena.com/image/square/e6fe840dfdcca31b69f48171e0de96a69b93595b/height=288;version=1;width=512/http%3A%2F%2Fwww.kmonos.net%2Fwlog%2Fsub%2Fdual%2F8.png)
 せっき~のゲーム屋さん ドルアーガの塔 乱数の工夫の正体
せっき~のゲーム屋さん ドルアーガの塔 乱数の工夫の正体
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。 CEDECの講演 「ゲーム世界を動かすサイコロの正体 ~ 往年のナムコタイトルから学ぶ乱数の進化と応用」 より、 乱数を使った ドルアーガの塔の 迷路生成のアリゴリズムについて紹介です。 講演内容は、こちらです http://sekigames.gg-blog.com/Entry/288/ 講演者の方も、 「ナムコの乱数を取り上げるなら、ドルアーガの塔をせざるえない」 という程、外せない内容との事です 「このテーマだけで講演時間を全て使っても説明しきれない」 (講演では、時間の関係で 触りのみでしたので ある程度、せっき~の解釈で補完しています) -------------------------------------------------------------------
 Google for Work 公式ブログ: Cloud Datastore でランキング処理を 1 時間から 5 秒に短縮
Google for Work 公式ブログ: Cloud Datastore でランキング処理を 1 時間から 5 秒に短縮
2014年9月8日月曜日 Cloud Datastore でランキング処理を 1 時間から 5 秒に短縮 Google for Work、 Cloud Platform GBU ソリューションアーキテクト 佐藤一憲 本記事は Google Cloud Platform サイト向けのソリューション ペーパーとして筆者が執筆し先日公開された「Fast and Reliable Ranking in Datastore」を要約したものです。ジョブ アグリゲーションやタスク キューのシャーディングなどの設計パターンを適用して、Google App Engine におけるランキング処理時間を大幅に短縮する方法を紹介しています。 ランキング処理の難しさ 株式会社アプリボットでリード エンジニアを務める鈴木智明氏は、多くの大規模なゲームサービスで直面する問題であるランキング処理に取り組んでいました
 [CEDEC 2014]「ゲーム世界を動かすサイコロの正体 〜 往年のナムコタイトルから学ぶ乱数の進化と応用」 - 4Gamer.net
[CEDEC 2014]「ゲーム世界を動かすサイコロの正体 〜 往年のナムコタイトルから学ぶ乱数の進化と応用」 - 4Gamer.net
[CEDEC 2014]ナムコ作品で見る乱数の歴史。「ゲーム世界を動かすサイコロの正体 〜 往年のナムコタイトルから学ぶ乱数の進化と応用」レポート ライター:箭本進一 神奈川のパシフィコ横浜で行われた,ゲーム開発者向けイベントCEDEC 2014の最終日である2014年9月4日,「ゲーム世界を動かすサイコロの正体 〜 往年のナムコタイトルから学ぶ乱数の進化と応用」という講演が行われた。 登壇したバンダイナムコスタジオ HE技術部 加来量一氏 この講演のユニークな点は,旧ナムコの作品を「乱数」という視点から振り返るということだ。バンダイナムコスタジオ HE技術部のプログラマーである加来量一氏は,旧ナムコの初期作品50本を解析し,それぞれの時代でどのような乱数が使われていたかを特定した。そこから見えてくる乱数技術改良の歴史を見ていくというのが,講義の主旨なのである。 1980年代のナムコアーケ
![[CEDEC 2014]「ゲーム世界を動かすサイコロの正体 〜 往年のナムコタイトルから学ぶ乱数の進化と応用」 - 4Gamer.net](https://cdn-ak-scissors.b.st-hatena.com/image/square/10648ed5c0d1a42db95e0d3f4eae3942f992f59b/height=288;version=1;width=512/https%3A%2F%2Fwww.4gamer.net%2Fgames%2F042%2FG004287%2F20140905040%2FTN%2F001.jpg)
 grepの代わりにsort,uniqで代用 - jarp,
grepの代わりにsort,uniqで代用 - jarp,
■ findでサイズが0のファイルをマークする -printfでサイズを表示するようにして、sedなりで変更するという方法が一般的だと思うが、 findだけで可能なのかやってみた。 準備。 % mkdir tmp % repeat 9 echo foo > tmp/$[++i].txt % touch tmp/0.txt % ls -l tmp 合計 36 -rw-r--r-- 1 eban eban 0 2014-07-01 23:23:59 0.txt -rw-r--r-- 1 eban eban 4 2014-07-01 23:23:52 1.txt -rw-r--r-- 1 eban eban 4 2014-07-01 23:23:52 2.txt -rw-r--r-- 1 eban eban 4 2014-07-01 23:23:52 3.txt -rw-r--r-- 1 eba
 なんでGCCはa*a*a*a*a*a を (a*a*a)*(a*a*a) に最適化できないの?っと
なんでGCCはa*a*a*a*a*a を (a*a*a)*(a*a*a) に最適化できないの?っと
c - Why doesn't GCC optimize a*a*a*a*a*a to (a*a*a)*(a*a*a)? - Stack Overflow 俺は科学技術計算の数値計算の最適化をしてたんだけどさ。GCCはpow(a, 2)をa*aにしてくれるんだな。うん。で、pow(a, 6)は最適化されずに、ライブラリ関数であるpowを呼んじゃうんだ。パフォーマンス的に最悪。(Intel C++ Compilerはpow(a,6)のライブラリ関数呼び出しを消し去ってくれるんだけどな) どうもよくわからんのが、pow(a, 6)をa*a*a*a*a*aで置き換えて、GCC 4.5.1をオプション"-O3 -lm -funroll-loops -msse4"で使ったら、mulsd命令を5個使う。 movapd %xmm14, %xmm13 mulsd %xmm14, %xmm13 mulsd
 ビットごとの秘法と技法 から
ビットごとの秘法と技法 から
最も右のビットの位置を知る法 TAOCP 7.1.3はbitwise tricks and techniques(ビットごとの秘法と技法)で楽しい話題が満載だ. このブログで以前取り上げたビットスワップもそこにある. 今回の話は計算機にある語xの最も右にある1のビットの位置を計算するもので, x = 0なら1のビットはないから, エラーか不定とするか無限大とするかだが, その辺はどうでもいいのでx≠0 の場合を考える. xに対してこの位置をρ(x)で表すので, 位置を求めるアルゴリズムをρ関数という. ρは右(right)のRに対応するギリシア語のアルファベット(小文字)である. これに対し最も左のビットはTAOCPではleftのLのギリシア語のλという. λはLisp屋にはちょっと困る命名だ. 二進法での計算に慣れている人は, 最も右の1のビットを取り出すのが簡単なことは知っている. x

 Counting Bloom Filterを試す - Negative/Positive Thinking
Counting Bloom Filterを試す - Negative/Positive Thinking
はじめに 悩み多き年頃なので、進捗ダメです。 KVS見てるときに出てきた、次元圧縮っぽさがあるBloom Filterを試してみる。 Bloom Filterとは 「ある要素が集合に含まれるか否か?」を扱えるデータ構造 要素をそのまま保存せず、ハッシュ値にしたものを配列に保存する アルゴリズム サイズがMの配列A[]を用意し、すべて値を0にしておく 要素の追加 K個の独立なランダムハッシュ関数(0〜M-1を返す)を使い、要素をK個のハッシュ値にする 配列Aでハッシュ値のindexのところを1にする(値がなんであっても) 要素の検索 追加時と同様にハッシュ値にし、すべて1になっていれば、要素が含まれると判断する 他の組み合わせでも1となってしまう組み合わせがあるために、「間違って要素がある、と判断してしまう可能性」がある=偽陽性 MやKを調整する事で、記憶容量と偽陽性のトレードオフを実現でき

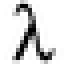 計算機プログラムの構造と解釈 第二版
計算機プログラムの構造と解釈 第二版
[ 目次, 前節, 次節, 索引 ] 2014-03-06 更新 [ 目次, 前節, 次節, 索引 ]
 d.y.d. - シミュレーション問題について
d.y.d. - シミュレーション問題について
20:43 13/12/31 本 今年読んで面白かった本ベスト20。 自分が今年読んだ基準なので遙か昔に出版された本も多数含みます。 しかもジャンル分けもせず適当に混ざっています。 ここ数年読書メーターでまとめてたんですけど今年ないみたいだし、 本棚機能もログインしていないと見られないようになってしまったみたいだし、 こちらで。 カクリヨの短い歌 和歌を詠むとその歌に応じた異能が発動するという能力バトルもの…というと情緒が飛んでしまいますかね。 読み終わったときはそうでもなかったのだけど、後からじわじわ来て、気づいたらこの話のことばかり考えるようになっていました。なんというか、歌を、この歌に込められた思いはこう…等々ロジカルな解題として語ってしまうのは勿体ないと思うんですよ。たとえば一面の桜吹雪、たとえば夜咲く紫陽花の花、その景色をただ再現するだけ、その具象が聴き手に何かを感じさせたならそ

 x86のMMUはチューリング完全である
x86のMMUはチューリング完全である
jbangert/trapcc · GitHub The Page-Fault Weird Machine: Lessons in Instruction-less Computation | USENIX x86のMMU、つまりは割り込みとメモリ変換テーブルは、チューリング完全であることの証明。割り込みとメモリ変換テーブルを活用して、プログラムカウンターを一切進めず、ひたすら割り込みを続けるだけで、任意の演算が可能になる。もちろん条件分岐だってオーケーだ。 このテクニックを使えば、カーネルモジュールのバイナリにとても解析が面倒な難読化処理を施すことができる。なぜなら、通常のインストラクションは実行しないから、何をしているのか、通常のインストラクションを追うだけでは一見して明らかではないからだ。そもそも、既存のKGDBなどは、あまりに頻繁な割り込みがかかるため、まともに機能しなくなるようだ

 いつからその方法で偏りのない乱数が得られると錯覚していた? - アスペ日記
いつからその方法で偏りのない乱数が得られると錯覚していた? - アスペ日記
私はつい最近まで勘違いしていました。 ここのページに書いてあるような方法で、一様分布する整数が得られると。 int random(int n) { return (int)(( rand() / (RAND_MAX + 1.0) ) * n); } この方法、一見すると実に一様分布が得られそうに見えるんですよね。 どういう思考回路を通っているかというのを自己分析すると、次のような感じです。 1. rand() では 0〜RAND_MAX のランダムな整数が得られる。 2. それを RAND_MAX + 1 で割ると、[0, 1) に一様分布する実数が得られる。 3. [0, 1) の一様な実数を n 倍して小数点以下を切り捨てたら、0 から n-1 に一様分布する整数が得られる。 これの罠なところは、1 と(特に)3 が正しいというところだと思います。 ただ、2 がダウト。 思いっきりダウ

 ソートキラー改 - d.y.d.
ソートキラー改 - d.y.d.
01:19 13/07/06 ソートキラー改 ここまでのあらすじ: → ソートの実装を渡すと、 自動でその実装の苦手な入力を作ってくれる ソートキラーを作りました。 → でも遅い。元々のソート処理が O(f(n)) として O(n2 f(n)) 時間かかる。 → あっ O(n3 + f(n)) になった! …という最後のステップを、コードは書いたのだけど説明どこにも書いてなかったのでメモ書きです。 本当にメモ書きであんまりわかりやすく書いてないので、気になる人だけ読んで下さい。 あと、特にたいしたことではないのでアルゴリズム得意な人には自明だと思われます。 説明 古いバージョンも新しいバージョンも、やっていることの流れは、こうです。 要素xは要素yより {小さい,大きい,わからない} の3状態を記録した n×n の表を準備。 初期値は "わからない"。 ソート関数に「xはyより小さいですか
 Boost.Lockfree ロックフリーキューの制限 - Faith and Brave - C++で遊ぼう
Boost.Lockfree ロックフリーキューの制限 - Faith and Brave - C++で遊ぼう
Boost 1.53.0時点のロックフリーキューは、要素型Tがtrivially copyable(memcpy可能な型)であることを要求します。そのため、ユーザー定義型の多くはロックフリーキューに格納できません。 #include <boost/lockfree/queue.hpp> int main() { boost::lockfree::queue<std::string> que(3); // エラー! } In file included from main.cpp:3:0: boost_1_53_0/boost/lockfree/queue.hpp: In instantiation of 'class boost::lockfree::queue<std::basic_string<char> >': main.cpp:7:41: required from here bo

 GoogleがB-tree実装のSTLコンテナを公開
GoogleがB-tree実装のSTLコンテナを公開
C++ containers that save memory and time cpp-btree - C++ B-tree - Google Project Hosting Googleが、B-tree実装のSTLコンテナー(map, set, multimap, multiset)を発表した。 多くのSTLの実装では、map, set, multimap, multisetは、Red-Black treeで実装されている。Googleの発表によれば、B-tree実装のコンテナーは、赤黒木実装に比べて、速度が上がり、しかもメモリ消費量も削減できるとしている。 紹介まで。 B木は一つのノードに複数の要素を格納する。これにより、ポインターなどのオーバーヘッドを低減でき、メモリ消費量の削減につながる。また、複数の要素を一括してノードに詰め込むため、速度向上もあるのかもしれないが、そのへんはよ
 古くて新しい自動迷路生成アルゴリズム - やねうらおブログ(移転しました)
古くて新しい自動迷路生成アルゴリズム - やねうらおブログ(移転しました)
最近、ゲーム界隈ではプロシージャルテクスチャー生成だとか、プロシージャルマップ生成だとか、手続き的にゲーム上で必要なデータを生成してしまおうというのが流行りであるが、その起源はどこにあるのだろうか。 メガデモでは初期のころから少ないデータでなるべくど派手な演出をするためにプロシージャルな生成は活用されてきたが、ゲームの世界でプロシージャル生成が初めて導入されたのは、もしかするとドルアーガの塔(1984年/ナムコ)の迷路の自動生成かも知れない。 なぜ私が迷路のことを突然思い出したのかと言うと、最近、Twitterで「30年前、父が7年と数ヶ月の歳月をかけて描いたA1サイズの迷路を、誰かゴールさせませんか。」というツイートが話題になっていたからである。 この迷路を見て「ああ、俺様も迷路のことを書かねば!俺様しか知らない(?)自動迷路生成のことを後世に書き残さねば!」と誰も求めちゃいない使命感が

 1024cores - Case Study: MultiLane - a concurrent blocking multiset
1024cores - Case Study: MultiLane - a concurrent blocking multiset
This is about the MultiLane : a concurrent blocking multiset paper. Go and read it first, it's just 4 pages including references and an appendix. Ok, I did not expect that you do that anyway :) It describes a way to improve scalability of a producer-consumer system by means of partitioning. Basically, it presents a way to wrap any producer-consumer queue in order to get a queue with the same prope

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


 いつからFIFOがスケールしないと錯覚していた
いつからFIFOがスケールしないと錯覚していた Google Code Archive - Long-term storage for Google Code Project Hosting.
Google Code Archive - Long-term storage for Google Code Project Hosting.